예전에 개발 팀장으로 있을 때 인턴으로 들어와 함께 일했던 동생과 오랜만에 술자리를 가졌다.
근황 얘기를 하면서 내가 이직 준비중이라고 하니, 동생이 본인 회사 면접 준비 해보라면서 면접에 대한 얘기를 했다.
본인 회사에서 주로 묻는 질문중의 예시로 한가지 질문을 해 주었다.
Java에서 String을 사용할 때 왜 조심해야 한다고 생각하나요?
순간 머릿속이 복잡해졌다.
자바 개발만 5년째 하고 있지만, 막상 그 질문을 정리해서 설명하려니 선뜻 말이 나오지 않았다.
"String은 불변 객체라서 연산할 때마다 객체가 새로 생성되고, 그게 쌓이면 GC에 부담을 준다"
이 정도 설명밖에 하지 못했다.
대답을 하고 나서도 마음 한켠이 찝찝했다.
틀린 말은 아니지만, 어딘가 부족하다는 느낌이 계속 남았다.
String이 왜 실무와 면접에서 이렇게 자주 언급되는지,
정말로 조심해야 할 포인트가 GC 하나뿐인지 스스로 확신이 없었기 때문이다.
그래서 이 글에서는, JVM 관점에서 Java String을 사용할 때 왜 '조심해야 한다'고 말하는지를 다시 정리해보려고 한다.
막연한 성능 이슈 이야기가 아니라,
객체 생성, 메모리 사용, 문자열 결합, 그리고 실무에서 자주 마주치는 패턴들을 중심으로 차근차근 짚어볼 예정이다.
✅ String은 왜 불변(immutable)인가?
Java에서 String이 불변 객체라는 사실은 대부분 알고 있다.
한 번 생성된 문자열은 내용을 바꿀 수 없고, 변경이 필요한 경우에는 항상 새로운 String 객체가 만들어진다.
이 설계는 단순한 구현 선택이 아니라, Java 언어와 JVM 전반에 깊게 연결된 결정이다.
가장 먼저 떠올릴 수 있는 이유는 안정성이다.
String은 파일 경로, 클래스 이름, 환경 변수, 네트워크 요청, SQL, 로그 메세지 등 시스템 전반에서 광범위하게 사용된다.
만약 문자열이 가변 객체였다면, 한 곳에서 수정된 문자열이 의도치 않게 다른 로직에 영향을 주는 일이 발생할 수 있다.
특히 여러 스레드가 같은 문자열을 참조하는 환경에서는 문자열이 불변이라는 사실 자체가 강력한 안전장치가 된다.
또 하나의 중요한 이유는 성능 최적화와 캐싱 전략이다.
Java에는 문자열 리터럴을 재사용하기 위한 String Pool이 존재한다.
"hello" 같은 리터럴은 매번 새로운 객체를 만드는 대신, 이미 존재하는 동일한 문자열을 재사용한다.
이 방식이 가능한 이유 역시 String이 불변이기 때문이다.
마지막으로, String은 HashMap의 key처럼 hash 기반 컬렉션에서 자주 사용된다.
불변이기 때문에 hash 값이 변하지 않고, 컬렉션의 동작이 안정적으로 유지된다.
결국 String의 불변성은 스레드 안정성, 메모리 재사용, 컬렉션 안정성을 동시에 만족시키기 위한 선택이다.
다만 이 선택의 대가로, 문자열을 변경하는 모든 순간마다 새로운 객체가 생성된다는 점을 반드시 인지하고 있어야 한다.
✅ String 연산은 JVM 메모리에서 어떻게 동작할까?
1️⃣ JVM 메모리 구조부터 짚고 넘어가자

Java 애플리케이션이 실행되면, JVM은 메모리를 역할별로 나누어 관리한다.
String과 직접적으로 관련 있는 영역은 크게 Stack과 Heap이다.
먼저 Stack 영역에는 메서드 호출 정보와 지역 변수, 그리고 객체를 가리키는 참조(reference) 가 저장된다.
여기에는 실제 객체 데이터가 아니라, “이 객체는 Heap의 어디에 있다”는 주소 정보만 들어간다.
반면 Heap 영역은 실제 객체 인스턴스가 생성되는 공간이다.
new String()이든, 문자열 연산의 결과든, String 객체 자체는 모두 Heap에 생성된다.
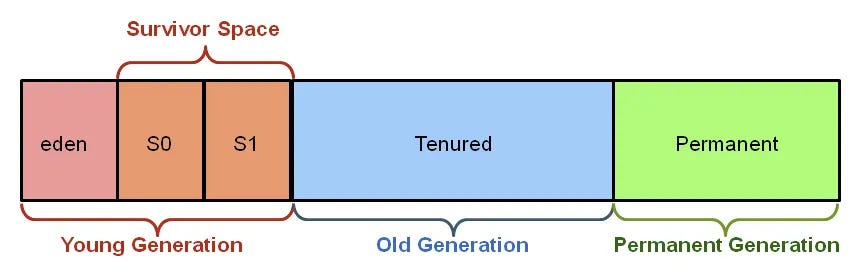
Heap 내부는 다시:
- Young Generation (새로 생성된 객체)
- Old Generation (오래 살아남은 객체)
으로 나뉘는데,
문자열 연산에서 문제가 되는 객체들은 대부분 Young 영역에 대량으로 생성됐다가 빠르게 사라진다.
2️⃣ String 객체는 JVM 메모리 어디에 생성될까?

String은 조금 특이하다.
모든 String 객체는 Heap에 생성되지만,
그 중 일부는 String Pool이라는 별도의 관리 영역에서 재사용된다.
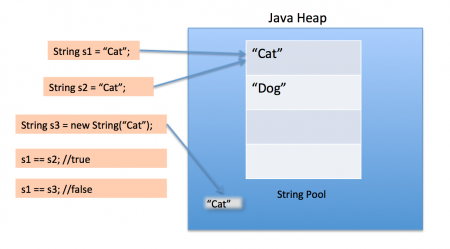
예를 들어:
- "Cat" 같은 문자열 리터럴 → String Pool
- new String("Cat") → 일반 Heap 객체
String Pool 역시 Heap의 일부이지만,
“공유 가능한 문자열만 모아둔 공간” 이라는 점에서 의미가 있다.
중요한 건 이 둘 모두 불변 객체라는 사실이다.
즉, 한 번 생성된 문자열은 수정되지 않고,
변경이 필요한 순간마다 새로운 String 객체가 Heap에 만들어진다.
3️⃣ 이제 문자열 연산을 JVM 흐름으로 보자
다음과 같은 코드가 있다고 가정해보자.
String result = "a" + "b";이 코드는 단순해 보이지만, JVM 입장에서는 다음과 같은 과정을 거친다.
먼저 컴파일러는 문자열 결합을 내부적으로 StringBuilder 기반 코드로 변환한다.
그리고 실행 시점에서는:
- StringBuilder 객체가 Heap에 생성되고
- "a", "b"가 내부 버퍼로 복사된 뒤
- toString()이 호출되면서 새로운 String 객체가 Heap에 생성된다.
즉, 문자열 하나를 만들기 위해:
- 임시 객체(StringBuilder)
- 내부 배열 복사
- 최종 String 객체 생성
이라는 단계를 거친다.
❗️반복문에서 문제가 커지는 이유
이 연산이 반복문 안으로 들어가는 순간, 상황이 달라진다.
문자열을 누적하는 구조에서는:
- 매 반복마다 새로운 String 객체가 생성되고
- 이전 String은 더 이상 참조되지 않아 garbege가 된다
- 이 객체들은 대부분 Young Generation에 쌓였다가 빠르게 수거된다
결과적으로 JVM은:
- 객체 생성 비용
- 메모리 복사 비용
- 잦은 Young GC
를 계속 감당하게 된다.
그래서 "String을 많이 쓰면 GC가 늘어난다"는 말의 정확한 의미는,
String 연산이 Heap에 단명 객체를 대량으로 만들어내는 구조를 쉽게 만들기 때문이다.
✅ String vs StringBuilder - 무엇이 어떻게 다를까?
앞에서 살펴본 것처럼, String 연산에서 문제가 되는 지점은 불변 객체라는 특성 때문에 발생하는 반복적인 객체 생성이다.
이 문제를 해결하기 위해 Java가 제공하는 대표적인 도구가 바로 StringBuilder다.
StringBuilder는 String과 달리 가변 객체(mutable)다.
한 번 생성된 이후에도 내부 상태를 변경할 수 있고,
문자열을 누적하는 과정에서 새 객체를 계속 만들지 않는다는 점이 가장 큰 차이점이다.
1️⃣ StringBuilder는 JVM 메모리에서 어떻게 동작할까?
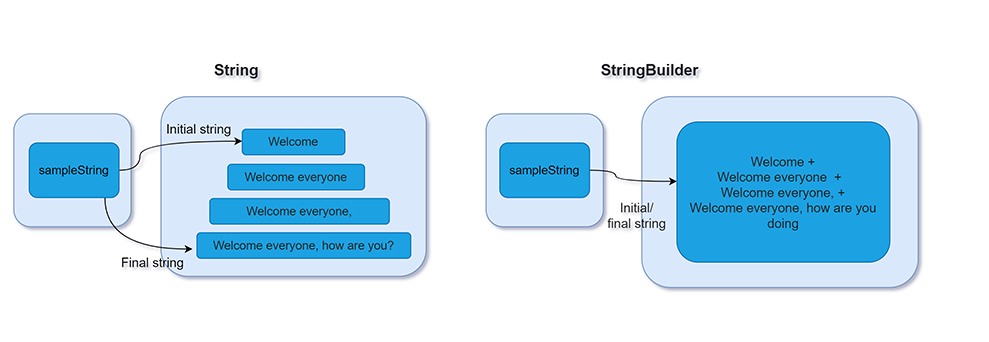
StringBuilder는 내부적으로 문자 배열(char[] 또는 byte[])을 버퍼로 유지한다.
문자열을 추가할 때마다 새로운 객체를 만드는 대신,
이 내부 버퍼에 내용을 계속 덧붙이는 방식으로 동작한다.
예를 들어, 문자열을 누적하는 코드가 있다고 가정해보자.
- StringBuilder 객체는 단 한 번만 Heap에 생성된다
- append() 호출 시, 내부 버퍼에 문자열이 추가된다
- 버퍼가 부족해질 경우에만, 더 큰 배열을 새로 만들어 복사한다
- 모든 작업이 끝난 뒤, toString()을 호출하면
- 그 시점에 한 번만 새로운 String 객체가 생성된다
즉, 문자열을 100번 이어 붙이더라도
중간 과정에서는 String 객체가 계속 생기지 않는다.
이 점이 String 연산과 결정적으로 다른 부분이다.
2️⃣ 코드로 이해하기
💡String을 사용한 문자열 누적
String sampleString = "Welcome";
sampleString = sampleString + " everyone";
sampleString = sampleString + ",";
sampleString = sampleString + " how are you?";
JVM에서 실제로 벌어지는 일
이 코드는 겉보기엔 sampleString 하나만 계속 바뀌는 것처럼 보이지만, 실제로 매 줄마다 새로운 String 객체가 생성된다.
개념적으로는 이런 식이다:
String s1 = "Welcome";
String s2 = s1 + " everyone"; // "Welcome everyone"
String s3 = s2 + ","; // "Welcome everyone,"
String s4 = s3 + " how are you?"; // "Welcome everyone, how are you?"- s1, s2, s3, s4 → 모두 다른 String 객체
- 변수 sampleString은 마지막 s4만 참조
- s1, s2, s3는 참조가 끊어져 GC 대상
💡StringBuilder를 사용한 문자열 누적
StringBuilder sampleString = new StringBuilder();
sampleString.append("Welcome");
sampleString.append(" everyone");
sampleString.append(",");
sampleString.append(" how are you?");
String result = sampleString.toString();
JVM 관점에서의 차이
- StringBuilder 객체는 한 번만 생성
- 내부 버퍼에 문자열이 계속 추가됨
- 중간 결과를 위한 String 객체는 생성되지 않음
- toString() 호출 시점에서만 최종 String 객체 1개 생성
3️⃣ 그래서 언제 무엇을 써야 할까?
정리하면 기준은 명확하다.
- 문자열 결합이 한두 번이고, 가독성이 중요한 코드
→ String과 + 연산을 사용해도 문제 없다 - 반복문 안에서 문자열을 누적하는 구조
→ 반드시 StringBuilder를 사용하는 것이 좋다 - 멀티스레드 환경에서 하나의 문자열을 여러 스레드가 수정해야 하는 경우
→ StringBuffer 또는 명시적인 동기화 고려
대부분의 문자열 관련 성능 이슈는 String 자체의 문제라기보다,
누적 문자열 처리에 맞지 않는 도구를 사용한 결과인 경우가 많다.
여기까지 정리하면
이제 질문에 이렇게 답할 수 있다.
Java에서 String을 사용할 때 조심해야 하는 이유는,
불변 객체 특성상 문자열 연산 과정에서 단명 객체가 대량으로 생성되고
반복되는 경우 GC 부담과 성능 저하로 이어질 수 있기 때문이다.
마무리
String은 Java에서 가장 자주 사용되는 클래스 중 하나지만,
그만큼 아무 생각 없이 사용하기 쉬운 객체이기도 하다.
이번 글에서는 “String은 불변이라서 GC 부담이 된다”라는 한 줄 설명 뒤에 숨겨진
JVM 메모리 구조, 객체 생성 흐름, 그리고 문자열 연산의 실제 동작을 차근차근 정리해보았다.
중요한 건 String을 피하자는 게 아니라, 어떤 상황에서 어떤 비용이 발생하는지 알고 선택하는 것이다.
특히 반복되는 문자열 누적과 같은 패턴에서는 String과 StringBuilder의 차이가 곧 성능 차이로 이어진다.
다음 글에서는 “String + 연산도 내부적으로 StringBuilder를 쓰는데,
그럼 우리는 왜 여전히 문자열 연산을 조심해야 할까?”라는 질문을 중심으로 컴파일러 최적화의 한계와 반복문에서 성능 차이가 발생하는 이유를 이어서 정리해보려고 한다.
'학습 > CS' 카테고리의 다른 글
| [Java] Optional - 사용 목적, 이점, 사용법 (1) | 2024.09.05 |
|---|---|
| 인증 방식 (Cookie & Session & Token) (0) | 2023.02.10 |
| 이중 연결 리스트 & List 자료구조 선택하기 (0) | 2023.02.08 |
| 프로파일 - LinkedListAddEnd (0) | 2023.02.06 |
| 프로파일 - LinkedListAddBeginning (0) | 2023.02.06 |